목차
【 강의 24 】 전문기술의 응용범위
❏ 하테나의 데이터로 검색엔진 만들기
검색엔진을 만들 때 중요한 요소 중 하나인 역 인덱스( inverted index)에 대한 설명
역 인덱스의 두 가지 기본요소
- Dictionary
- Postings
❏ 하테나 다이어리의 전문 검색 - 검색 서비스 이외에 검색 시스템 이용
‣ RDB 로 처리 -확장성 측면에서 문제
구현 방식
- 유저가 글을 작성하면 해당 글에 포함되어 있는 키워드를 전부 추출
- 이 단어들과 블로그의 연관성을 데이터베이스의 레코드로서 저장
>> 단어 "perl" 을 검색하면 해당 단어가 포함된 블로그 목록을 표시
<문제 > 레코드 수가 많아지면서 확장성 측면에서 많은 제한 발생
‣ 검색기술의 응용
"포함하는 블로그" : 특정 단어를 포함하는 블로그 검색
- 검색엔진기술을 응용하여 구현
- 다이어리의 사양에 특화시킨 방법으로 검색속도 향상
- 불필요한 결과정렬 방식을 제외: 날짜순으로만 정렬
- 각 글의 id 를 하테나 다이어리의 사양에 특화시킨 방법으로 저장
❏ 하테나 북마크의 전문 검색 - 세세한 요구를 만족시키는 시스템
"마이 북마크 검색" : 각 개인이 북마크한 개인 데이터로부터 검색하는 시스템
- 각 사용자가 북마크를 하는 타이밍에 각 사용자별로 검색 인덱스 구현 및 갱신
- 직접 구현 함으로써 세세한 요구사항에 대응
【 강의 25 】 검색 시스템의 아키텍처
❏ 검색 시스템이 완성되기까지
‣ 검색 시스템의 여섯 단계
- 크롤링
- 저장
- 인덱싱
- 검색
- 스코어링
- 결과표시
각 단계별 과제
- 대상의 문서를 가져올 플랫폼을 정해서 웹 크롤러를 만들어서 대량의 문서를 가져오는 작업
- 대량의 문서를 어떻게 저장할 것인가 (하나의 DB에 저장하면 해당 DB에 문제가 생기면 복구 불가 → 분산 DB에 저장해야하는 문제)
- 가져온 문서로 부터 인덱스(고속으로 검색하기 위한 구조)를 구축
- 검색 결과를 어떻게 정열할 것인가, 어떤 순서로 보여줄 것인가
❏ 다양한 검색엔진
‣ 오픈소스
- grep
- Namazu : http://www.namazu.org/index.html.en
- Hyper Estraier : https://dbmx.net/hyperestraier/
- Apache Lucene : https://lucene.apache.org/
등 다양한 오픈소스가 있다.
❏ 전문 검색의 종류
‣ grep 형
- 검색 대상 문서를 처음부터 전부 읽는다 O(mn) text: m, word: n
- 계산량을 개선한 방법 : KMP(Knuth-Morris-Pratt, O(m + n)) BM(Boyer-Moore, 최악O(mn), 최선O(n/m))
- 즉시성이 좋고, 검색누락이 없으며, 병렬화나 쿼리 확장이 용이(쿼리에 정규표현 사용)
- UNIX 에서 유용한 명령어
- 대규모 환경에서 구현하기에는 무리가 있는 방식
‣ Suffix 형
- 문서를 검색 가능한 형태로 보유 - 전부 메모리에 올릴 수 있는 형태
- 데이터 구조: Tire, Suffix Array, Suffix Tree
- 이론적으로는 가능
- 정보량이 크고 구현하기 어려움
‣ 역 인덱스형 (주류)
- 실제 시스템에서 많이 채택되는 방식( Google)
- 단어(term)와 문서를 연관짓는 방식
- 즉시성 측면에서 뛰나지 못함 → 검색누락 발생 가능
- grep 처럼 문서가 변경되면 바로 검색결과도 바뀌는 방식은 어려움
【 강의 26 】 검색엔진의 내부구조
❏ 역 인덱스의 구조 - Dictionary + Postings
문서를 인덱스화 한다? → 아래의 그림을 말하는 것
아래의 그림에서 2번을 참고하면 각 단어에 연결되어있는 문서 번호가 있다.
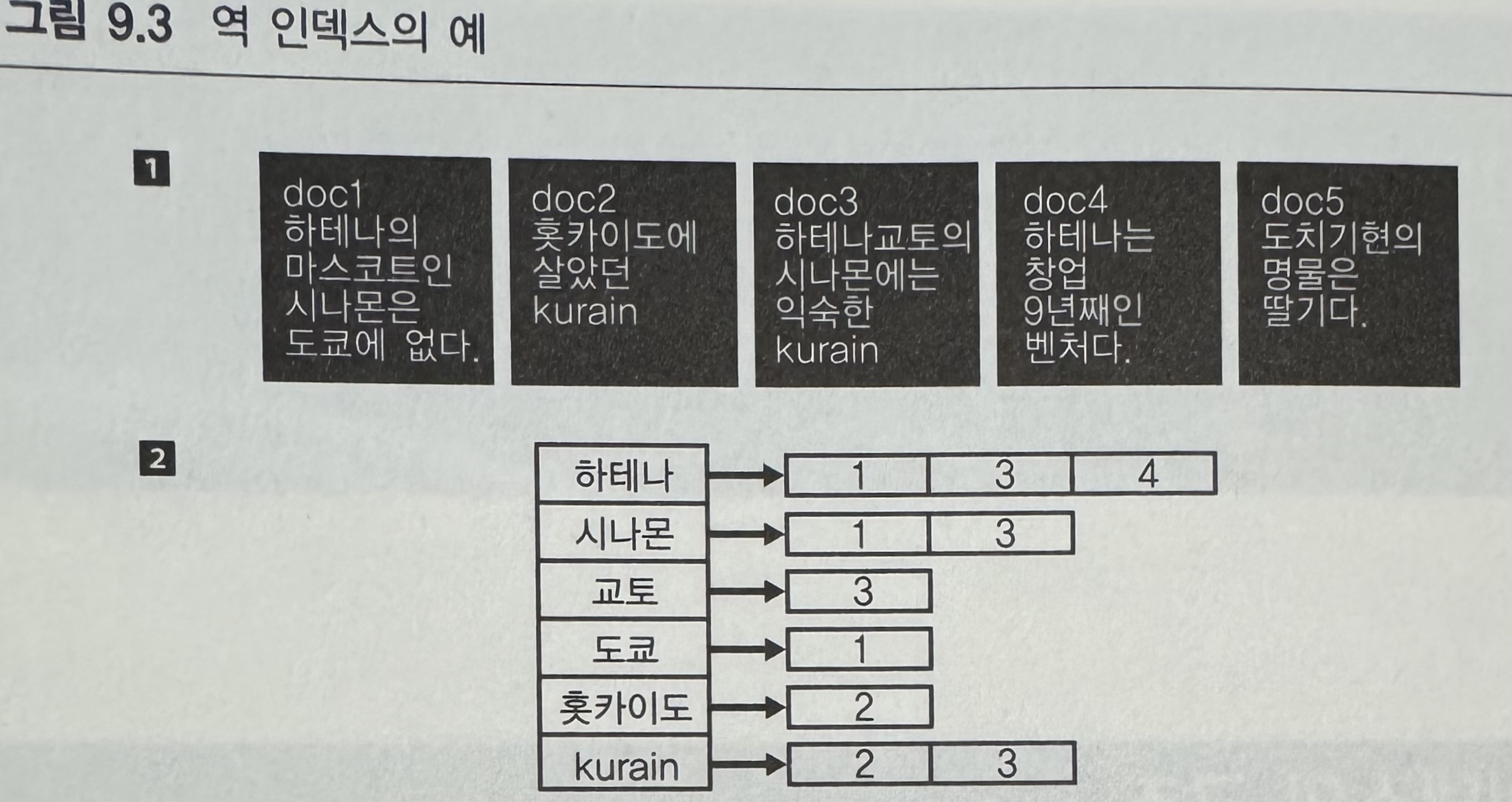
Dictionary? 좌측에 있는 단어(term)의 집합
Postings? 우측에 있는 번호들처럼 각 단어를 포함하고 있는 문서는 몇 번인지를 나타내는 것
(예) Dictionary 내에 있는 term: '하테나' 를 포함하고 있는 Postings 내에는 1, 3, 4 가 있다.
❏ Dictionary 만드는 법
문장에 있는 단어를 term으로 추출한다.
단어를 추출할때 사용가능한 방식들
- 사전 이용( Wikipedia)
- 형태소 분석
- n-gram 기법
- AC (Aho-Corasick) 법
*Trie 에서 패턴 매칭으로 매칭이 진행되다가 도중에 실패했을 경우, 되돌아오는 길의 엣지를 다시 Trie에 추가한 데이터 구조를 사용한 방법 (p175, 20강)
‣ 언어의 단어를 term 으로 다루기
- 사전과 AC법을 이용하는 방법
- 형태소 분석을 통하여 단어찾는 법 - 검색 누락 발생 가능
- stemming 이나 Lemmatizer 등을 이용하여 부분적 극복가능
‣ n-gram을 term 으로 다루기
- 텍스트를 n 자씩 잘라내는 방식 : "하테나 다이어리" -(2-gram)-> 하테 /테나 /나다 /다이 /이어 /어리
- 쿼리도 동일한 규칙으로 분할해야한다.
- 원하지 않는 결과가 나올 수도 있다.
- 東京都 문제 :
- 東京都 -(2-gram)-> 東京 / 京都
- 문서: "東京 타워와 京都타워" 라는 문서를 인덱싱했을때. 이 문서가 東京都로 검색했을때 검색된다.
- 東京都 문제 :
‣ 검색 시스템 평가와 Recall/Precision
재현률(Recall)/ 적합률(Precision)을 이용하여 검색 시스템에 특정 쿼리를 입력했을 때의 성능을 정량화 가능
- Recall : 검색 결과에 쿼리를 포함한 문서가 얼마만큼 포함되었는지를 의미 ( 올바른 결과의 수 / 적합한 결과 총수)
- Precision : 검색 결과가 얼마나 정확한 결과가 들어 있는지를 의미 ( 올바른 결과의 수 / 반환한 결과 총수)
n-gram 방식은 검색누락은 발생 안하지만 원하지는 않는 결과가 반환 → Recall이 우선
형태소 방식은 검색이 안되는 것도 있지만 원하지는 않는 결과가 반환되지 않음 → Precision 이 우선
팁
타이틀, 코멘트, URL을 대상으로 검색할 때는 n-gram 사용
본문 검색에는 단어기반을 사용
❏ 지금까지의 정리
검색엔진 중에 가장 많이 사용되는 방식은 역 인덱스 방식
역 인덱스 방식 : Dictionary + Postings 구조
Dictionary 를 만드는 방식에는 n-gram 과 형태소 분석을 기반으로 하는 방법이 있다.
❏ Postings 작성법
term 이 해당 문서 내에 출현 위치도 저장하는 경우 ( Full Inverted Index)
- 스피닛을 뽑아낼때 이 단어가 문장 내의 어디에 포함되어 있느지 바로 알수 있음
- 스코어링에도 도움
- 필터링에도 용이
문서 ID만을 저장하는 경우
- 정렬(오름차순/내림차순) → VB Code로 압축
- 어느 정도의 데이터의 압축률과 빠른 전개 성능
- 구조 term → 압축된 Postings List
- key-value 스토어에 적합
❏ Scoring 에 대한 보충
검색결과를 어떤 순서로 표시할 건지는 상당히 중요한 문제!!
예를 들어 Google은 문서의 중요성을 고려해서 랭킹을 매겨서 검색결과를 표시한다.
주요 알고리즘 : PageRank
PageRank + 검색어의 출현위치 + 이외 다양한 알리고리즘을 이용해여 문서의 중요성을 파악
문서의 중요도를 파악하는데 자주사용되는 알고리즘 TF/IDF 가 있다.
'책 > 웹 개발자를 위한 대규모 서비스를 지탱하는 기술' 카테고리의 다른 글
| [대규모서비스] [책] 12 장 확장성 확보에 필요한 사고방식 (2) | 2024.11.15 |
|---|---|
| [ 대규모 서비스 ] [ 책 ] 11 장 대규모 데이터 처리를 지탱하는 서버/인프라 입문 (3) | 2024.11.02 |
| [대규모 서비스] [책] 7장 : 21 강 하테네 북마크의 기사 분류 (0) | 2024.10.10 |
| [대규모 서비스] [책] 7 장: 20강 하테나 다이어리의 키워드 링크 (0) | 2024.10.10 |
| [대규모 서비스] [책] 7 장 알고리즘 실용화: 19강 알고리즘과 평가 (0) | 2024.10.08 |