캐시 교체 알고리즘
- 미래의 참조를 미리 알지 못함
보관할 객체와 삭제할 객체를 동적으로 결정하는
온라인 알고리즘
(문제점)
- 캐싱 대상이 되는 객체들의 크기와 인출 비용이 균일하지 않음
- 객체를 가지고 있는 근원지 서버의 위치 및 특성에 따라 객체를 캐시로 읽어오 비용이 다르기 때문
- URL에 대응하는 파일 단위로 캐싱이 이루어지기 때문
1) 교체 알고리즘의 성능 척도
전통적인 캐싱환경
- 객체의 크기와 인출 비용이 균일
- 연구된 기법 : 페이징, 버퍼캐싱
=> 참고 가능성이 높은 객체를 캐시에 보관하여 캐시적중률(Hit Rate: HR) 높이는 것이 목표
(1) 캐시적중률
(2) 바이트적중률
(3) 지여감소률
(4) 비용절감률
2) 참조 가능성의 예측
- 효율성 평가 기준
- 미래의 참조 가능성을 얼마나 잘 예측 하는가
- 전통적인 캐싱 기법 ( Least Recently Used:LRU , Least Frequency Used:LFU)
- 참조 가능성을 과거 참조기록에 의해 평가
- 즉, 최근 참조 성향과 참조 빈도에 근거 -> 미래의 참조성향을 예측
- 전통적인 교체 알고리즘이 과거의 참고 기록을 활용하는 방법
- LRU 알고리즘:
가장 최근의 참조 기록만을 활용
(-) 자주 참조되는 객체와 그렇지 않은 객체를 구분할수 없음 - LFU 알고리즘:
참조 횟수가 가장 적은 객체를 캐시에서 삭제
(-) 최근에 참조 되지않아도 오래전에 많이 참조된 객체에 높은 가치 부여
(-) 최근에 참조되기 시작한 객체를 캐시에서 삭제할 가능성 존재 - LRU-K 알고리즘
최근 K번째 참조된 시점 중에 현재시점과 가까운 것에 가치를 높게 평가
(-) K 번째 참조된 시점만을 고려하고 최근에 참조된 시점은 고려 안함 - LRFU(Least Recently Frequently Used)
각각의 참조 시점을 그 최근성에 근거해 고려 -> 최근의 참조일수록 기여도를 더 높게 계산
객체의 참조 가능성
- LRU 알고리즘:

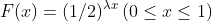
여기서,
λ = 0 인 경우 LFU 알고리즘과 동일한 방식, 객체 i 의 과거 참조 횟수를 뜻함
λ = 1 인 경우 LRU 알고리즘과 동일한 방식으로 동작
- 컴퓨터 프로그램의 참조 성향(program reference behavior)을 모델링에 고려되는 요소
- 시간지역성(temporal locality) : 최근에 참조된 객체가 다시 참조될 가능성이 높다
- 인기도(popular) : 참조 횟수가 많은 객체일수록 또다시 참조될 가능성이 높다
- 웹캐시의 교체 알고리즘들이 이러한 요소를 반영하는 방법
- 시간지역성의 관점 -> 객체의 직전 참조 시각을 활용
- LNC-R 알고리즘 : 과거 K 번째 참조 시각을 이용
- LRU-K 알고리즘 : 이질형 객체??를 위한 캐싱 기법에 맞게 활용
- 이질형 객체란?
- 참조 인기도 측면
- 객체의 참조 횟수 이용
- 객체의 참조 횟수 + (추가) 노화 기법 -> 캐시오염(cache pollution) 을 방지
- 노화 기법: 오래전에 이루어진 참조에 대해서는 참조 횟수를 계산할때 가중치를 줄이는 방법
- 캐시오염 : 오래전에 참조 횟수가 많았다는 이유로 최근에 참조되지 않는 객체가 캐시에 남아 있는 현상
- 시간지역성과 참조 인기도 모두 고려
- LRV 알고리즘과 MIX 알고리즘 : 직전 참조 시각 + 객체의 참조 횟수
- LNC-R 알고리즘 : 과거 k 번째 참조 시각 + 참조 인기도
- GD-SIZE : 시간지역성에 기반 + 참조 인기도 결합
- LUV : LRFU 을 웹캐시의 특성에 맞게 일반화 시킨 방법 + 과거의 모든 참조 기록을 이용
- 시간지역성의 관점 -> 객체의 직전 참조 시각을 활용
3) 객체의 이질성에 대한 고려
- 캐시적중률을 높이고자 하는 알고리즘
- SIZE 와 LRU-MIN
- 크기가 작은 객체에 높은 가치를 부여 -> 많은 객체를 보관 -> 캐시적중률 향상
- 비용절감률을 높이고자 하는 알고리즘
- 웹 객체의 참조 가능성에 대한 예측치 + 그 객체의 단위 크기당 비용을 곱해 객체의 전체적인 가치를 평가하는 방법
- LNC-R, SW-LFU, SLRU, LRV, LUV 알고리즘
- 노화매커니즘을 객체의 비용에 비례하는 감소치를 적용
- GD-SIZE 계열의 알고리즘
- 객체의 크기와 비용 고려
- 객체의 참조 가능성과 이질성 고려 안함
- 노화매커니즘을 모든 객체에게 동일한 값으로 적용
- 웹 객체의 참조 가능성에 대한 예측치 + 그 객체의 단위 크기당 비용을 곱해 객체의 전체적인 가치를 평가하는 방법
4) 알고리즘의 시간 복잡도
- 전통적인 캐싱 환경
- n개의 객체에 대한 시간 복잡도가 빅오(log n)를 넘지 않는 조건을 쉽게 만족
- 웹환경
- 문제점
- 빈 공간이 필요할 때마다 즉시 삭제할 객체를 선별필요 -> 시간적인 제약 존재
- 객체의 크기와 인출 비용이 이질적 -> 복잡도 상승
- 전통적인 캐시 교체 알고리즘 적용시 현실성 고려 필요
- 힙(heap) 자료구조 이용
- 이진 트리의 일종으로 주로 우선순위 큐를 구현하기 위한 자료구조
- 참조 시각을 이용하는 알고리즘에서는 객체의 가치가 시간이 지남에 따라 다르게 평가
-> 힙 자료구조 사용불가
-> 매 순간 자료의 가치를 새롭게 평가 필요 -> O(n)의 시간 복잡도 필요
- O(n)의 시간 복잡도 이용
근사적인 구현방법을 이용하여 알고리즘의 시간복잡도 감소
- LNC-R : 힙사용 + 주기적인 업데이트를 통해 근사적 구현
- MIX
- LRV :LRU 리스트를 객체의 가치에 따라 여러 개 두는 방법을 통해 근사적인 구현
- SLRU :LRU 리스트를 객체의 가치에 따라 여러 개 두는 방법을 통해 근사적인 구현
- LRU-MIN :LRU 리스트를 객체의 가치에 따라 여러 개 두는 방법을 통해 근사적인 구현
- PSS = SLRU를 근사적으로 구현한 알고리즘
- LOG2-SIZE = LRU-MIN을 근사적으로 구현한 알고리즘
- GD-SIZE 와 LUV = 최근 참조 시각을 이용하는 알고리즘 이지만 참조 되지 않은 객체들 간의 대소관계가 변하지 않는 성질 보유
-> 힙을 이용하여 효율적인 구현이 가능
- 문제점
